
Что такое цифровой двойник?
Про технологию цифрового двойника (англ. digital twin) в последние годы говорят очень много. В общем случае, цифровой двойник – это виртуальная копия процесса или физического объекта. Цифровой двойник состоит из комплекса математических моделей, которые постоянно получают данные из реальной среды. На основе этих данных уже строится и меняется сама цифровая копия.
Это технология применяется для тестирования гипотез. Она позволяет сэкономить деньги и выбрать наилучшее решение. Например, вы планируете расширять ассортимент в магазине. Если смоделировать ситуацию в виртуальной среде, можно понять, как часто будут осуществляться поставки, будут ли задержки из-за увеличивающихся объемов, справится ли приемка с объемом работы, будет ли наблюдаться каннибализация спроса, если планируется расширять линейку брендов и т.д. Таким образом, можно будет заранее определить все слабые места.
При управлении запасами цифровой двойник может быть использован для решения следующих задач:
- определение оптимального товарного запаса;
- планирование перемещений от поставщиков и между складами и торговыми точками;
- моделирование распределения запасов через распределительный центр;
- моделирование запасов при проведении промо-акций;
- определение рисков дефицита, перетарки, недопоставки и частичной поставки
- анализ возможных вариантов событий;
В Forecast NOW! мы используем технологию цифрового двойника для прогнозирования и расчета оптимального товарного запаса. Это сложный и трудоемкий процесс, который затрагивает много факторов.
О том, что должна уметь современная система управления запасами, мы писали в статье «14 факторов, которые нужно учитывать при прогнозировании товарных запасов» .
Бизнес – это управление рисками в постоянно меняющейся среде. Чтобы показывать хорошие результаты и прибыль, нужно уметь оперативно реагировать на изменения. Но проанализировать и учесть все возможные варианты в физической среде практически невозможно, особенно если вводные данные меняются каждый день. А это реальность большинства торговых компаний.
Чтобы определить, какой оптимальный запас с точки зрения прибыли выгодно иметь компании на текущий момент, Forecast NOW! строит цифровую копию процессов управления запасами компании. Далее моделируются возможные варианты развития событий. Обычно делается около 100 тысяч экспериментов. На выходе из модели будет уже известно, с какой вероятностью будет продан тот или иной объем запасов. А это уже дает понимание того, сколько нужно заказать товара сегодня (или в другой день), чтобы обеспечить максимальную прибыль, поддержать нужный уровень сервиса или принять решение в соответствии с другими целями.
Как это работает на практике
Прежде чем погрузиться в детали, рассмотрим простой пример, как может работать технология для моделирования подбрасывания монеты.
Представим, что у нас есть обычная монета, которую можно подбросить. Любая монета не идеальна, т.е. подбросив её 100 раз, маловероятно, что 50 раз выпадет решка , а 50 – орёл. Скорее всего, вы получите соотношение 60/40, 48/42 или что-то подобное.
Если мы хотим получить статистически достоверные данные, то нужно подбросить эту монету много раз, например, 100 000. А это достаточно трудоемкая задача.
Чтобы не делать это вручную, мы максимально точно оцифруем монету. Повторим при этом все сколы, шероховатости, неровности и вмятины, учтем все законы физики и силы, действующие на эту монету. В итоге получится цифровой двойник монеты, максимально приближенный к реальной.
Теперь подбросим 100 000 цифровую копию монеты. Например, в результате мы получили, что 55 000 раз выпал орёл, а 45 000 – решка. Это позволяет нам говорить, что с 55% вероятностью в реальной жизни мы можем рассчитывать на то, что выпадет решка.
Что теперь с этими вероятностями делать? Здесь нам на помощь придет пример с прогнозом погоды. Если синоптики говорят, что сегодня с 80% вероятностью будет облачно, а с 20% вероятностью пойдет дождь, то вы уже знаете, что есть риск промокнуть, хоть и небольшой.
Они могли бы пренебречь этой вероятностью, усреднить значения и просто сказать: «Сегодня будет облачно». В случае, если у вас запланирована длительная прогулка, то было бы очень неприятно промокнуть. С другой стороны, зная, что сегодня есть небольшая вероятность дождя, вы можете подстраховаться и взять зонт. Если же вы весь день планируете провести в машине, то вам может быть дождь нет так страшен, а зонт и не нужен вовсе.
Но в любом случае лучше знать о возможности дождя и иметь возможность принять решение о необходимости зонта, чем этого не знать.
Если перенести эту аналогию на управление запасами, то получим сопоставление вероятностных моделей и классических. Под классическими подразумеваются такие методы, как среднедневные продажи, скользящая средняя, АRIMA, метод Хольта-Винтерса и другие более сложные алгоритмы. Эти методы обычно реализованы в виде модуля в 1C или таблиц в Excel. Их объединяет то, что на выходе получается одно число, как прогноз спроса. И именно на него мы и ориентируемся. Так, в соответствии со среднедневными продажами, если вчера мы продали 5 единиц, а сегодня 10, значит, прогноз на завтра будет 7,5 единиц товара. Но в действительности он может быть, как больше, таки меньше.
Вернемся к сравнению. Например, алгоритм показал, что спрос будет 25 сникерсов на следующей неделе. И дополнительных данных у нас нет. А что, если бы вы знали, что с 30% вероятностью, вы можете продать 50 сникерсов за эту неделю и получить прибыли в 2 раза больше? При этом у вас есть свободные денежные средства, на которые можете купить товар и место на складе.
Оценка спроса – это только одна из величин, которую можно посчитать вероятностно. Например, заказывая товара у поставщика, вы не можете быть уверены, что он привезет его вовремя. А если при этом вы будете знать, что риск срыва срока поставки составляет 40%, у вас уже есть возможность подумать. Можно оставить заказ в том объеме, что планировался, или увеличить его на случай избежания дефицита в будущем.
Знание вероятности всех возможных вариантов развития событий дает возможность более гибко и эффективно управлять запасами.
Теперь вернемся к цифровому двойнику и поговорим, как это работает в Forecast NOW!
На вход алгоритма поступает история продаж и остатков за прошлые периоды.
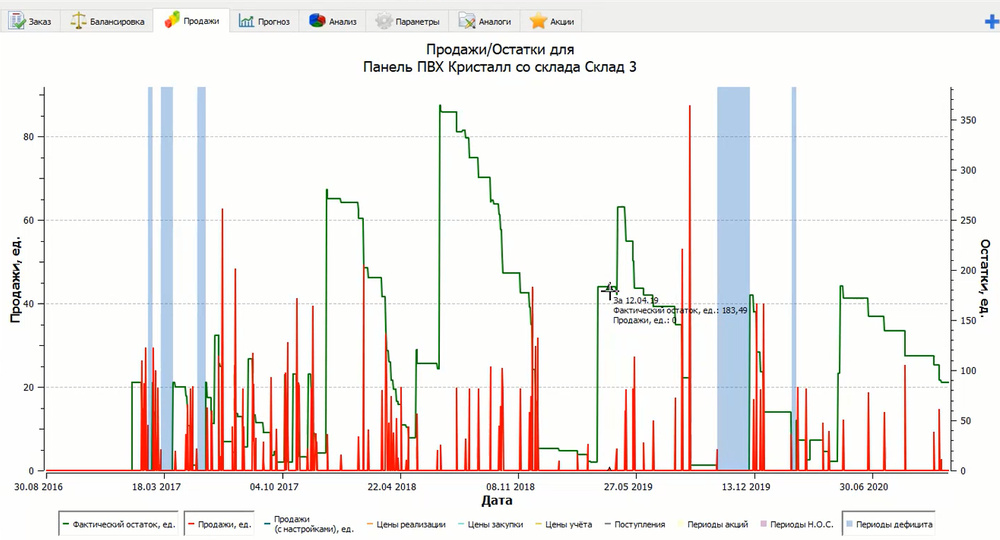
Рис. История продаж и остатков за 3 года.
Обычно история содержит периоды дефицита, аномальных всплесков продаж, изменений спроса из-за сезона, промоакций и т.д. Программа очищает продажи от всех этих периодов, превращая данные в историю спроса.
О том, зачем это нужно и как очистить историю продаж читайте в статье «Как подготовить историю продаж, чтобы получить корректный прогноз спроса».
После того, как история очищена, программа стоит цифровую копию товара. Снимаются все возможные характеристики спроса по этому товару. Например:
- как часто были периоды, что товар продается каждый день;
- как часто были периоды, что товар продается через день;
- как часто были периоды, что товар продается через 2,3,4 и более дней;
- как часто товар продавался в количестве 1 шт. сегодня, 2 шт. завтра, 3 шт. через день и т.д.;
- как часто товар продавался в количестве 2 шт. сегодня, 2 шт. завтра, 3 шт. через день и т.д.;
- и другие варианты.
То есть для каждого товара на конкретный день формирования заказа строятся все возможные частоты продаж, которые были в прошлом периоде. Если завтра появятся новые данные по продажам за прошедший день, то цифровая копия будет построена заново, и все модели будут пересчитаны с учетом новых данных.
После того как готова цифровая копия конкретного товара, мы можем смоделировать возможные варианты развития событий в будущем, т.е. как будет изменяться спрос на этот товар. Для этого программа проводит 100 000 экспериментов в виртуальной среде.
Посмотрим на пример моделирования.
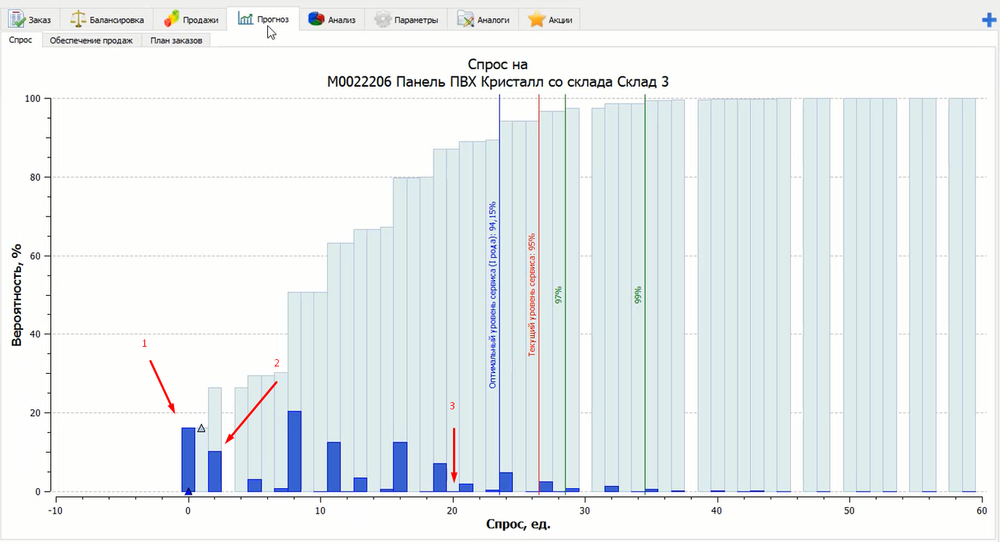
Внизу по горизонтали показаны возможные объемы спроса, а высота темно-синих столбцов – это вероятность возникновения этого спроса. Другими словами это количество экспериментов, в которых будет продано ровно такое количество товаров:
- Столбец №1 показывает, что в 16 000 экспериментах не было продано ни одного товара. Это означает, что с вероятностью 16% не будет продано ни одного товара.
- Столбец №2 показывает, что в 10 000 экспериментах было продано 2 единицы товара. Это означает, что с вероятностью 10% будет продано ровно 2 единицы товара.
- Столбец №3 показывает, что менее 100 экспериментов показали, что получится продать ровно 20 единиц товара. Значит, вероятность такой продажи меньше 0,01%. При этом вероятность продать 19 товаров составляет около 8% (столбец рядом). Такой разброс может быть связан с особенностями спроса на данный товар.
- И т.д.
В результате работы такой модели мы получаем распределение вероятностей продаж, которое не усредняет никакие показатели.
Подробнее о том, как работает Forecast NOW! читайте в статье "Схема работы программы".
Что дальше с этим делать?
Наша задача покрыть определенное количество возможных сценариев развития событий. Например, целевой уровень сервиса равен 95%. На рисунке выше – это красная линия. Объем спроса на её уровне – 27 единиц товара. Слева от этой черты все темно-синие столбцы составляют 95% всех возможных сценариев развития событий, т.е. за 95 000 проведенных экспериментов в цифровой модели товара спрос находился в границах от 0 до 27 штук.
Значит, если положить на склад 27 единиц товара, то мы сможет обеспечить уровень сервиса 95%. Если же нужен уровень сервиса 99% (зеленая линия на рисунке), то нужно на склад положить уже 35 единиц товара.
Этот пример описывает цифровую копию для одного конкретного товара. При реальной эксплуатации для каждого отдельного товара строится индивидуальная цифровая копия с присущими только ему характеристиками. Далее программа моделирует возможные варианты развития событий уже под каждый конкретный товар.
Понятно, что такой объем гипотез протестировать в реальной среде не представляется возможным, поэтому классические методы (средние продажи, Arima, метод Хольта-Винтерса и др.) усредняют итоговые значения спроса, что часто может сказываться на качестве и точности прогнозов. В противовес этому, когда мы строим цифровую модель товаров, мы работаем индивидуально с каждым SKU и рассматриваем все возможные варианты изменения спроса для него.

