

В последние десятилетия, а особенно в последние годы, использование искусственного интеллекта, машинного обучения и нейронных сетей набрало обороты. Не стала исключением и область управления товарными запасами.
Сейчас можно найти множество упоминаний, как применяется искусственный интеллект в прогнозировании спроса и товарных запасов. И компании стремятся всячески это подчеркнуть. Но мало кто рассказывает, как именно используются нейронные сети, а особенно про сложности и проблемы, с которыми приходится сталкиваться.
Мы начали использовать нейронные сети и генетические алгоритмы в Forecast NOW! еще до бума популярности ChatGPT и других LLM и продолжаем следить за изменениями. В статье рассказываем, почему при всей популярности искусственного интеллекта и нейросетей мы все же отказались от этих технологий для задач, связанных с прогнозированием.
Почему прогнозирование с помощью нейросетей оказалось эффективно только для 4-6% товаров?
Разрабатывая систему Forecast NOW!, мы закладывали в неё принципы самообучающихся нейросетей. И нужно заметить, для продукции регулярного спроса, то есть примерно для 4-6% товаров, представленных в стандартном супермаркете, они показывали отличные результаты.
Почему именно для 4-6%? Во-первых, прогноз на ближайший день или неделю получается в виде единственного числа. Значит, необходимо дополнительно учитывать и страховой запас. Он, как правило, рассчитывается через нормальное распределение или через распределение Пуассона. Но нормальное распределение свойственно только 4-6% товаров из всего ассортимента магазина, которые покупают регулярно и стабильно, и корректно рассчитать страховой запас можно только для них. Во-вторых, для нейросетей на входе должно быть большое количество обучающих примеров по конкретному товару. Если товар имеет разреженные продажи, то получить достаточно обучающих примеров невозможно. Разреженные продажи, как это ни странно, имеют 94-96% ассортимента типового магазина. Сочетание этих двух факторов и дает те самые 4-6%.
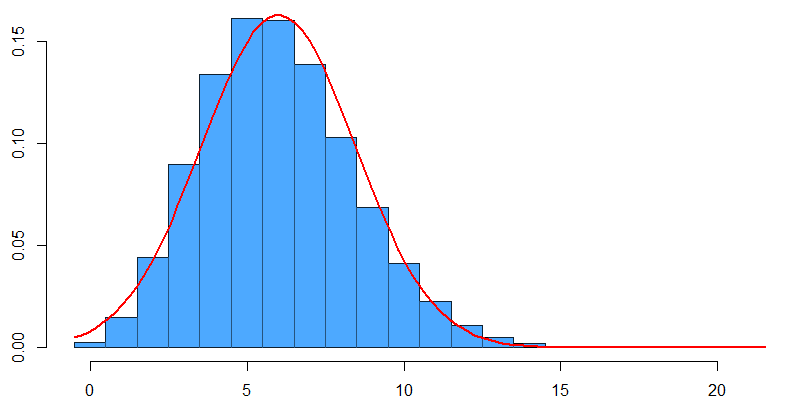
Использование нейронных сетей для прогнозирования в Forecast NOW!
Что касается использования прогнозирования на основе нейросетей в Forecast NOW!, то для каждого товара система индивидуально рассчитывала спрос и необходимый для заказа объём товаров. При расчёте учитывалось влияние огромного пула параметров на спрос: от прогноза погоды для продаж мороженого до прогноза продаж автомобилей для реализации запасных частей. При этом на входе модель могла обработать любые данные, полученные от пользователей. Единственное условие – они должны быть оцифрованы и корректно подготовлены.
Основные сложности при работе с нейросетями
По мере накопления данных нейросеть самостоятельно дообучалась, анализировала влияние различных показателей для того, чтобы улучшить прогнозы. Например, прогноз погоды являлся довольно важным фактором для продаж мороженого. В этом случае нейронные связи укреплялись. Факторы, которые практически не оказывали влияние, наоборот, ослаблялись. Здесь также стоит отметить про опасность данных, которые могут не отличаться высокой точностью. В данном случае – это прогноз погоды. А его необходимо подавать на вход и в дальнейшем. И так как он имел достаточно большой вес, это было рискованно при работе с большим количеством магазинов и товаров.
Однако даже такая, казалось бы, идеальная система, могла давать сбои. Дело в том, что нейронные сети очень требовательны к входным данным. Несмотря на возможность учёта большого количества параметров, это усложняет всю систему. А чем сложнее система, тем труднее её обучить, контролировать и, соответственно, получить качественный результат.
Чтобы контролировать усложнение модели, вводился «штраф за сложность» для нейросети. В противном случае был риск, что сеть с большим количеством нейронов, связей и степеней свободы будет использовать каждую связь для конкретного типа примеров. Другими словами, она могла заучивать «правильные» ответы, как студент, который не понимает материал, и впоследствии их показывать на выходе. Иногда, чтобы понять, есть ли корреляция между факторами, и какой из них необходимо учитывать, приходилось проводить предварительные анализы. Таким образом, мы либо сильно усложняли модель, либо сами должны были понимать, какие факторы важны, а какие нет.
Проектирование входных данных
Вообще, вопрос входных данных – достаточно сложная тема и, чтобы подробно её раскрыть, потребуется отдельная статья. Здесь мы затронем только основные моменты. Входные данные должны быть хорошо подготовлены и тщательно обработаны. Для этих целей у нас были разработаны отдельные алгоритмы, которые их нормализовывали, выравнивали плотность.
Данные на входе должны быть определенного объёма, «нарезаны» определённым образом, как примеры, на которых можно обучаться. Необходимо создать библиотеку обучающих и контрольных примеров. Проблема проектирования входных данных является одной из ключевых и напрямую влияет, будет ли обучаться нейронная сеть. Отдельно приходилось заниматься определением параметров, которые важны на входе. Какие признаки будут оптимальными для тех или иных товаров.
Подробнее об этом можно прочесть в нашей публикации:
Структура нейросети и проблемы с обучением
Помимо проектирования входных данных, вставал вопрос проекта самóй нейросети. Насколько сложной она должна быть? Сколько слоёв и нейронов должна содержать? Мы испробовали множество подходов: начиная от генетических алгоритмов, которые могут оптимизировать, то есть искать оптимальную структуру нейронной сети, и заканчивая эвристическими алгоритмами, которые позволяли исходя из сложности входных данных понять адекватную сложность внутренности нейронной сети.
Стоит сказать и про проблемы с обучением нейросетей, которые нам приходилось решать. Первая из них – это переобучение. Был большой риск натренировать нейросеть именно на тех результатах, которые служили примером. В дальнейшем она просто начинала их повторять. Чем больше факторов мы добавляли, тем больше становилась сложность системы и повышался риск, что она могла «зазубрить» ответы.
При изменении входных данных с другими параметрами на выходе могли получиться совершенно неопределенные значения. Для решения этой задачи исторические данные делились на две части: обучающая и контрольная для проверки. Таким образом, у нас ещё больше сокращалось число обучающих примеров.
Вторая большая проблема – застрять в локальном минимуме, недообучить нейронную сеть. Была вероятность, что алгоритм остановится на каком-то субоптимальном решении. Чтобы выйти из этого положения, приходилось подключать к решению другие нейросети, которые образовывали комитет и путем голосования определяли прогнозный спрос.
Другим вариантом было применение генетических алгоритмов. Они воздействовали на веса нейронной сети путём мутации и скрещивания, тем самым заставляя её измениться, что впоследствии помогало обучаться дальше и повышать точность прогноза. Однако использование данных подходов в реальных условиях сильно осложняло применение системы.
Черный ящик
Ещё одним аргументом за отказ от использования прогнозирования на основе нейронных сетей было единственное число как прогноз спроса на выходе из алгоритма. Что делать с этим числом в дальнейшем, оставалось большим вопросом. Формирование заказов, опиравшееся на одну цифру, превращалось в игру на удачу. Так, кстати, работает и большинство классических математических алгоритмов. Справедливости ради нужно заметить, что есть возможность получения распределения вероятностей на выходе, а не единственное число. Но это не решало проблему с количеством входных примеров.
Главной же сложностью применения такой системы стало то, что организации и конечные пользователи не понимали, как работают эти алгоритмы, и достоверность полученных данных во многих случаях была под вопросом. Фактически мы получали «чёрный ящик». Понятно, что реальная компания не готова работать с тем, чего не понимает. Здесь мы пробовали применять различные технологии для получения объяснений от нейросети: такие, как извлечение правил. Но эти извлечённые правила были малопонятны для людей и зачастую содержали очень странные закономерности.
При этом использование нейронных сетей и генетических алгоритмов хорошо зарекомендовало себя там, где конечный результат можно легко проверить на правильность. Это такие задачи, как распознавание образов, текста, окружающей среды, например, для беспилотных автомобилей, а также задачи, решаемые популярными LLM – ChatGPT, DeepSeck, Claude и др. Ситуации, когда данные на выходе нельзя сразу проверить, по-прежнему несут большие риски для организаций, особенно, когда эти риски связаны с деньгами.
В итоге, несмотря на то что все описанные проблемы удалось решить, мы всё же поняли, что использование нейросетей и генетических алгоритмов для прогнозирования спроса – не самый лучший метод.
Также, у нас есть отдельная статья о том, что умеет ИИ в прогнозировании спроса и чего нет.
Вероятностные модели
После долгих экспериментов мы остановились на вероятностных моделях. Вероятностное прогнозирование позволяет получить на выходе не просто цифру, а набор чисел – вероятностей. Алгоритмы гораздо менее сложные по своей сути и от этого более эффективные и устойчивые к входным данным. А главное – понятны конечным пользователям, а значит, и компании.
При этом прогнозы на основе нейронных сетей вполне могут применяться для этих целей и показывать хорошие результаты. Но здесь нужна поддержка аналитиков, которые готовы дополнительно вручную анализировать множество факторов по разным товарам, анализировать ошибки отклонения, постоянно проверять работу моделей. Но когда речь идет о работе в автоматическом режиме для расчета 10 000 товаров и больше, это неприменимо.
Отличие вероятностных алгоритмов от классических
Чем же отличаются вероятностные алгоритмы от классических? Важно отметить, что использование стандартных отклонений, нормального распределения и тому подобных оценок не является вероятностным алгоритмом. Для лучшего понимания проведем аналогию с классическими методами. Например, считая, сколько бутылок вина нужно заказать на неделю в один из своих магазинов, вы можете воспользоваться одной цифрой, которую получили на выходе из системы. Но эта цифра будет, скорее всего, отражать среднее значение, полученное на основе данных из предыдущих периодов. Прибавьте к этому страховой запас, и у вас получится приблизительное значение для заказа. Теперь добавим к этому еще прогнозы для 20 000 других товаров магазина. В итоге мы получим данные для заказа. Но что, если не получится всё продать, как планировалось, и денежные средства будут заморожены в запасах? Или, наоборот, будет дефицит товаров? Или часть товаров скоропортящиеся, и непонятно, как быстро получиться их продать? В этом случае можно посадить множество аналитиков, которые вручную будут просчитывать возможные риски и выбирать оптимальный запас, опираясь на полученный прогноз и на своё экспертное мнение.
Теперь представим, что, заказывая вино на неделю, на выходе вы получаете распределение вероятностей спроса:
- с 88% вероятностью купят не более чем 100 бутылок вина,
- с 89% вероятностью – не более чем 102 бутылки вина,
- с 90% вероятностью – не более чем 103 бутылки вина,
- и так далее…
У вас уже появляется выбор, какой процент спроса удовлетворить. И, главное, вы можете этим управлять. То есть вы больше не зависите от прогноза в виде одного числа и стандартизированного нормального распределения, а можете оценить риски и выбрать наиболее прибыльный вариант в соотношении: удовлетворение спроса/затраты. Так, если вы держите 100 бутылок вина, то:
- с 1% вероятности вы недопродадите 2 бутылки вина,
- с 2% вероятности вы недопродадите 3 бутылки вина,
- и так далее…
Вы можете взвесить эти риски, оценить их влияние в деньгах, понять, насколько оптимально удовлетворять 88% спроса. Взвесив риски для каждой вероятности, вы сможете найти оптимальную точку баланса, то есть сколько бутылок вина выгоднее всего хранить. Теперь прибавим такое же распределение вероятностей для еще 20 000 товаров из первого примера, и вы сможете управлять товарными запасами более эффективно. А при возникновении исключительных ситуаций, которые происходят постоянно на рынке, вы сможете максимизировать свою прибыль. Отметим, что, если вы используете классический метод с нормальным распределением или стандартными отклонениями для определения страхового запаса, для каждого товара распределение этих рисков будет иметь одинаковую форму, что не соответствует реальности.
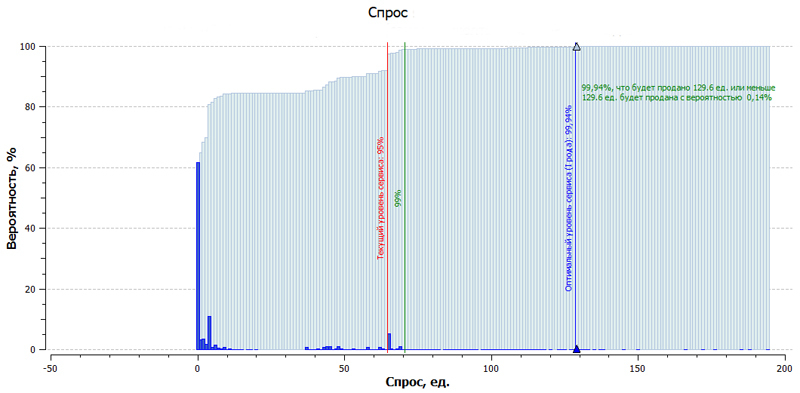
Итоги: вероятностные модели работают эффективнее
Как показала наша практика, а это более 500 исследований на реальных данных предприятий различных отраслей розницы и дистрибуции, вероятностные модели зарекомендовали себя гораздо лучше, чем системы с использованием нейронных сетей и машинного обучения в логистике. Вероятностные модели позволяют максимально точно рассчитывать оптимальную точку баланса запаса для каждого товара, то есть определяют такое количество товаров, которое нужно хранить на складе, чтобы минимизировать суммарные потери. При этом в нашей системе учитываются риски: затраты на хранение, возможный дефицит, списания испорченной продукции, стоимость замороженных денежных средств, вероятность которых может исчисляться в сотых долях процента!

