
Вы подготовили данные для расчётов, «очистили» их от дефицита, акций, сезонности и прочих факторов. Об этом мы говорили в статье «Как подготовить историю продаж, чтобы получить корректный прогноз спроса» . Как теперь спрогнозировать спрос, чтобы понять, какое количество товаров нужно заказать на будущее?
Сегодня разберёмся, какие существуют подходы и методы прогнозирования потребительского спроса и как с ними работать.
Методы прогнозирования спроса: их эволюция
Итак, какие методы прогнозирования спроса существуют? На графике ниже видно, как они развивались.
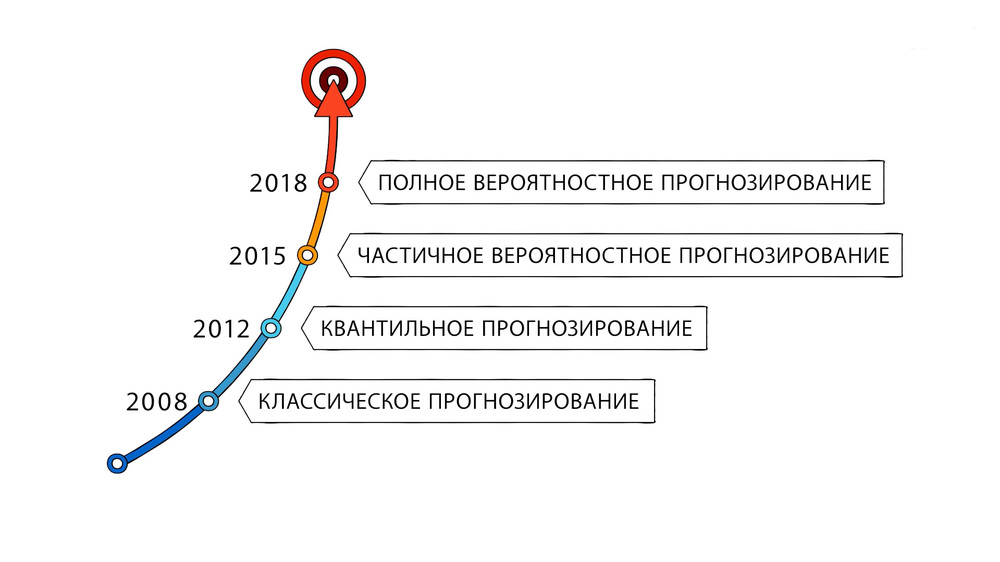 Мы видим, когда и какие методы прогнозирования спроса считались рабочими. Так «расцвет» классических методов пришёлся приблизительно на 2008-2009 гг., затем активнее стали использовать квантильное прогнозирование и постепенно перешли к методам вероятного прогнозирования. Конечно, временные рамки здесь условные, ведь несмотря на то, что уже появились более современные методы, классическое прогнозирование до сих пор используется.
Мы видим, когда и какие методы прогнозирования спроса считались рабочими. Так «расцвет» классических методов пришёлся приблизительно на 2008-2009 гг., затем активнее стали использовать квантильное прогнозирование и постепенно перешли к методам вероятного прогнозирования. Конечно, временные рамки здесь условные, ведь несмотря на то, что уже появились более современные методы, классическое прогнозирование до сих пор используется.
Подробно о том, как развивались алгоритмы прогнозирования спроса, смотрите в ролике на нашем youtube-канале.
Экспертные модели прогнозирования спроса
Прежде чем перейти к разбору каждого метода в отдельности, поговорим о так называемых экспертных способах прогнозирования спроса. Они до сих пор часто используются на практике. В чём их суть: некий эксперт, который хорошо знает ассортимент, выставляет пороговые значения спроса по отдельным позициям.
Классический экспертный метод – способ минимакса, где для каждой позиции устанавливается максимальное и минимальное значение запаса. Если он опускается до какого-то минимума, формируется точка запаса, и мы заказываем товара столько, чтобы хватало до максимума.
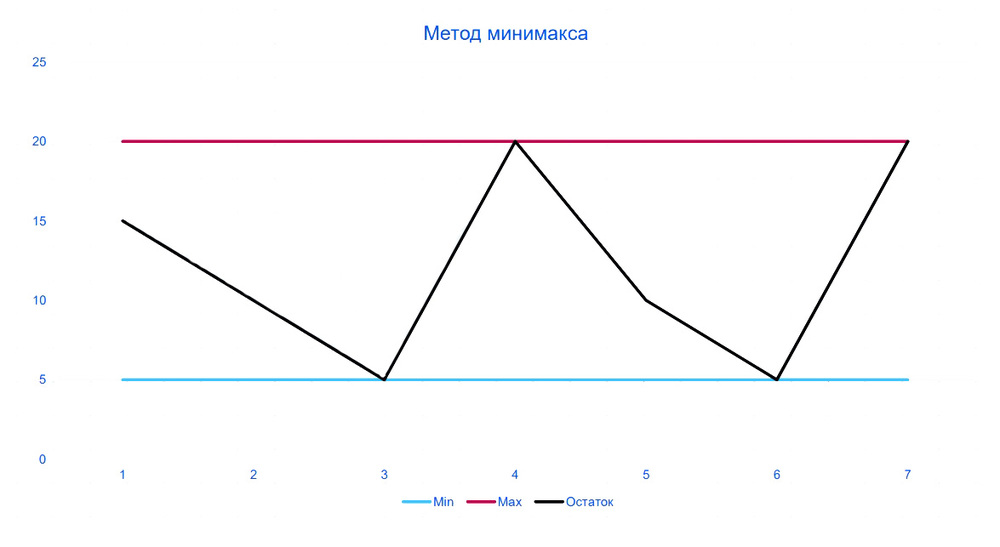 Недостаток этого метода в том, что мы не можем корректно выставлять и пересчитывать минимаксы по десяткам тысяч товарных позиций. Кроме того, спрос по товарам постоянно меняется. Возможно, такие методы прогнозирования потребительского спроса могут подойти для каких-то небольших объёмов. При широком ассортименте, множестве торговых точек и динамично меняющемся спросе применять такой метод прогнозирования нецелесообразно. Это может привести как к сверхзапасам, так и к дефицитам.
Недостаток этого метода в том, что мы не можем корректно выставлять и пересчитывать минимаксы по десяткам тысяч товарных позиций. Кроме того, спрос по товарам постоянно меняется. Возможно, такие методы прогнозирования потребительского спроса могут подойти для каких-то небольших объёмов. При широком ассортименте, множестве торговых точек и динамично меняющемся спросе применять такой метод прогнозирования нецелесообразно. Это может привести как к сверхзапасам, так и к дефицитам.
Общий принцип методов классического прогнозирования
На основании какого-то спроса в прошлом периоде мы можем спрогнозировать, какой спрос или какие продажи у нас будут в будущем. Общая особенность методов классического прогнозирования в том, что прогноз спроса на день, на неделю, на месяц (исходя из нашего периода расчёта) будет равен какому-то одному числу.
 Внутри классического прогнозирования могут использоваться разные модели прогнозирования спроса от простых до сложных. Например:
Внутри классического прогнозирования могут использоваться разные модели прогнозирования спроса от простых до сложных. Например:
- по средним продажам (SMA и т.д.)
- экспоненциальное сглаживание (простое и двойное) – ES
- авторегрессия (1 и 2 порядка) – AR
- Arima (AR+MA)
- Метод Хольта-Винтерса
- Нейронные сети и генетические алгоритмы (NN+GA)
Набор методов разный, но главная их особенность в том, что на выходе получается одно число.
Рассмотрим основные методы.
Расчёт по среднему (SMA), или простая скользящая средняя
Это один из самых простых и распространённых методов прогнозирования спроса, которым до сих пор пользуются многие компании.
Формула простого скользящего среднего(SMA) выглядит так:
Прогноз(t+1) = (1/(T+1)) *[Продажи(t)+ Продажи(t-1)+...+ Продажи(t-T)]
Для того чтобы просчитать спрос по этому методу, необходимо:
- Выбрать ширину окна Т, где Т указывает, за какой период мы будем усреднять продажи. Если мы управляем дневным спросом, то за 2-3 последних дня, 7 последних дней и т.д. Если считаем спрос по месяцам, то за последние 2, 3, 4, 5 месяцев.
- Для прогноза на следующий период будем брать среднее за выбранную ширину. Допустим, мы строим прогноз на 10-й день. Ширина окна 5 штук и, значит, мы берём среднее за последние 5 дней. Получили продажи за новый день и опять берём среднее за последние 5 дней. Так мы прогнозируем данные и наш спрос на будущий период.
- Продажи мы можем брать как подряд, которые шли в предыдущем периоде, так продажи за тот же период, в этом же месяце, в этом же году и т.д. Здесь можно гибко подходить к периоду расчёта данных, который мы берём для получения среднего.
Посмотрим, как работает такое прогнозирование на примере в Excel.
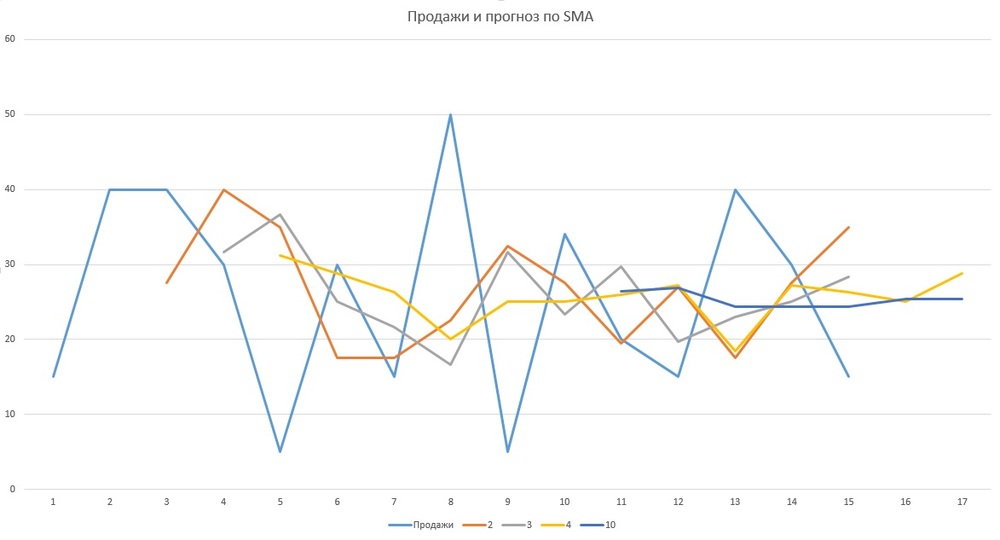

У нас есть ряд продаж, и дальше мы хотим построить прогноз. Продажи агрегированы по месяцам, и, допустим, мы хотим сделать прогнозы на помесячные периоды. Для этого выбираем ширину окна – считаем среднее за последние 2, 3, 4, 10 месяцев. Если выбираем ширину окна 2, а продажи в ноябре и декабре были 15 и 40 соответственно, то в январе в среднем прогнозируем 27,5, в феврале – 40.
Чем шире окно, тем ближе будут показатели к расчёту по средним за весь период. На графике это видно: синим цветом обозначены реальные продажи, остальные графики – это продажи с разной шириной окна.
Такой метод может подходить для хорошо продающихся товаров, которые гладко и стабильно продаются с небольшими колебаниями. За всю нашу практику он подошёл только одной компании. В остальных наших кейсах методы расчёта продаж по среднему дают достаточно большие погрешности и неэффективны с точки зрения управления товарными запасами. Они приводят к дефициту или излишним запасам.
Рекомендуем прочитать: Сравнение Forecast NOW! и
модели Простой скользящей средней (SMA, Simple Moving Average) — Суть алгоритма прогнозирования SMA заключается в усреднении значений продаж за определенный период. Идея алгоритма заключается в том, что в будущем будет продано столько, сколько в среднем было продано в прошлом.
На смену этому методу пришли различные расчёты по средневзвешенному среднему. Рассмотрим их особенности.
Метод по Шрайбфедеру, или метод средней взвешенной
Если в прошлом методе мы считали спрос по средним продажам, то в этом появляются различные веса разных месяцев. Что мы делаем?
- Рассчитываем продажи на один рабочий день прошедших месяцев. Если были какие-то выходные, важно знать количество рабочих дней, чтобы посчитать средние продажи за эти дни. Например, в феврале 28 дней, а в январе из 30 вы работали 25.
- Выбираем систему весов для прошедших месяцев. Какие-то данные будут более важными для построения расчётов, какие-то наоборот.
- Рассчитываем прогнозное потребление за 1 рабочий день будущего месяца, исходя из прошлых продаж и весов.
- Рассчитываем прогнозное потребление за месяц, исходя из числа рабочих дней.
Разберём на примере:
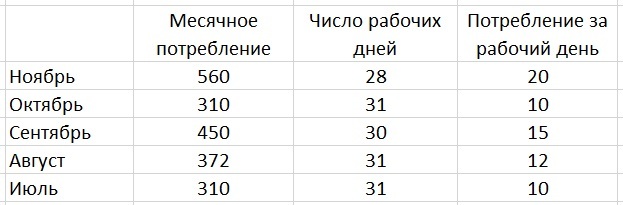 В первом столбце исходные данные по месяцам, и мы хотим построить на их основе прогноз на декабрь. Продажи в ноябре – 560 штук. Рабочих дней – 28. Потребление за один рабочий день – 20 штук.
В первом столбце исходные данные по месяцам, и мы хотим построить на их основе прогноз на декабрь. Продажи в ноябре – 560 штук. Рабочих дней – 28. Потребление за один рабочий день – 20 штук.
После того как мы получили месячное потребление для каждого месяца, используем систему весов. Шрайбфедер предлагает разные варианты системы весов. В данном случае мы взяли модель, в которой говорится, что недавние продажи более сильно влияют на наше построение прогноза.
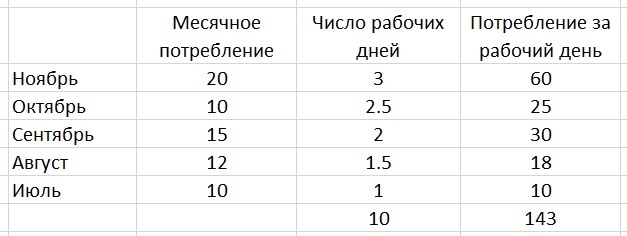 Вес для ноября – 3, для октября – 2,5 и т.д. Самый большой вес у прошлого периода, наиболее ближнему к тому, к которому мы проводим расчёт. В данном случае это ноябрь. Дальше каждый месяц умножаем на его вес. 20х3 = 60. После считаем сумму всех месячных потреблений, умноженных на вес – 143. Общая сумма весов – 10.
Вес для ноября – 3, для октября – 2,5 и т.д. Самый большой вес у прошлого периода, наиболее ближнему к тому, к которому мы проводим расчёт. В данном случае это ноябрь. Дальше каждый месяц умножаем на его вес. 20х3 = 60. После считаем сумму всех месячных потреблений, умноженных на вес – 143. Общая сумма весов – 10.
Прогноз на декабрь = 143/10* 28(число рабочих дней) = 400 штук
В книге «Эффективное управление запасами» Шрайбфедер предлагает множество схем весов, которые могут подходить для разных товаров. Например:
- Простая шестимесячная (или трёхмесячная) средняя. Это расчёт среднего с окном 6. То есть необходимо взять 6 месяцев и посчитать среднее за этот период.
- Для сезонных товаров он выделял либо простую сезонную среднюю, либо сезонную взвешенную среднюю. Если мы строим прогноз на декабрь, то берём данные за последнюю зиму, либо сезонную взвешенную среднюю. В данном случае декабрь значит для нас больше, т.к. мы делаем прогноз на месяц.
- Коэффициенты взвешенной средней. Это то, что было в нашем примере – 3, 2, 5 и на убыль.
То есть здесь есть какой-то предполагаемый набор весов. На нашей практике встречалось, что компания разрабатывает собственный набор весов. Работать так можно, но независимо от того, как ответственно мы подходим к расчётам этих весов, данный метод построения прогнозов имеют довольно большие ограничения.
Посмотрим пример расчёта по средневзвешенным продажам в Excel.
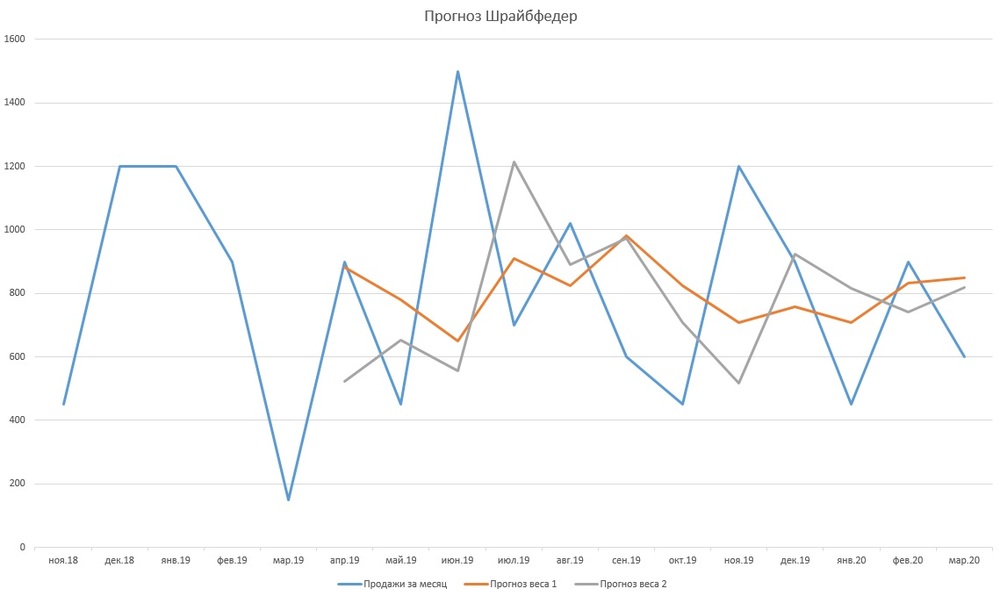
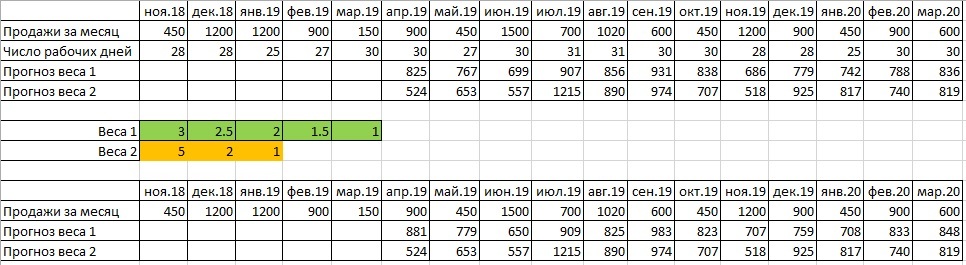
У нас есть ряд продаж, известно число рабочих дней в каждом периоде, и мы хотим построить прогнозы. Имеются прогнозы на 5 месяцев с весами от 3 до 1. И на три месяца с весами от 5 до 1. Продажи делятся на число рабочих дней, умножаются на вес этого месяца. Получившийся показатель делим на сумму весов и умножаем на число рабочих дней. Реализовать всё это в Excel достаточно просто. Логика такая: мы выбираем какую-то формулу весов, либо разработанную нами, либо предложенную в теории, и, исходя из этой системы весов, строим прогнозы.
Метод экспоненциального сглаживания (ES)
Это ещё одна из самых простых моделей прогнозирования спроса, которая также часто используется на практике. Здесь логика в том, что прогноз спроса зависит от двух факторов:
- продаж в прошлом периоде;
- прогноза спроса, построенного на этот период каким-то методом.
Мы задаём коэффициент сглаживания (α), учитывая два этих фактора. Чем больше коэффициент α, тем сильнее влияние последних продаж на прогноз (от 0 до 10).
Прогноз (t+1) = (1 – α)* Прогноз(t) + α * Продажи(t)
Проводим расчёт на нескольких α и выбираем оптимальный. Метод рабочий, но нужно понимать, что коэффициент сглаживания не будет учитывать сезонные, трендовые товары и т.д. Поэтому математики разработали метод, который на основе этого позволяет работать с товарами разного характера и сезонностью. Так появился метод Хольта-Винтерса.
Рекомендуем прочитать: Статья "Сравнение Forecast NOW! с методом экспоненциального сглаживания (ES)" - Метод ES — один из самых популярных, но работает ли он в реальных условиях нестабильного спроса? Мы сравнили его с Forecast NOW! и выяснили, когда он срабатывает, а когда подводит.
Метод Хольта-Винтерса
Формула сложная. Не будем разбирать её детально, а посмотрим на её логику.
Y^[t+h] = (a[t] + h * b[t]) * s[t - p + 1 + (h - 1) mod p]
h – на какой период в будущем считаем
Y^[t+h] - прогноз на период номер h
p – период сезонности (для недельной 7)
Мы строим прогноз на будущий период, и он зависит от множества факторов. Что внутри этой формулы на самом деле «зашито»? Мы выделяем три основных фактора – сглаживание, тренд и сезонность. Для каждого этого фактора мы берём свои коэффициенты от 1 до 10.
a[t] = [α * (Y[t]/s[t−p])] + (1-α) * (a[t-1] + b[t-1]) – сглаживание
b[t] = β * (a[t] - a[t-1]) + (1-β) * b[t-1] – тренд
s[t] = γ * (Y[t]/a[t]) + (1-γ) * s[t-p] – сезонность
α, β, γ – коэффициенты (от 0 до 1)
Мы посчитали сезонный фактор, трендовый фактор, определили экспоненциальное сглаживание, подобрали коэффициенты и получили прогноз спроса на будущий период. Метод Хольта-Винтерса подходит для сезонных и трендовых товаров, которые постоянно продаются. Посмотрим на его реализацию в Excel.
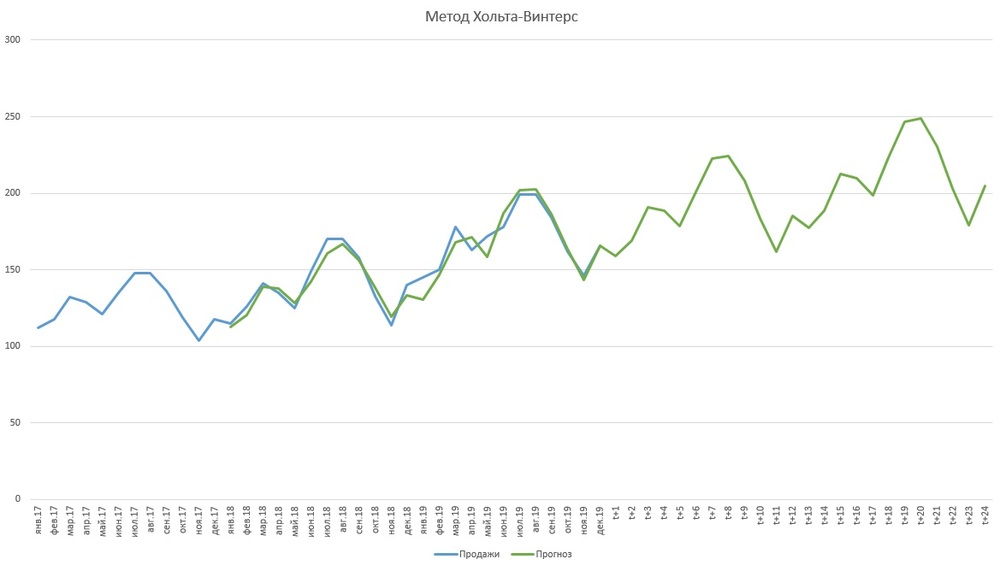

У нас есть помесячно агрегированные продажи. Первым делом мы посчитали сезонный фактор методом по среднему (деление реальных продаж на средние продажи за период). Получили коэффициенты сезонности. Также посчитали коэффициент тренда и построили прогноз. Главное, что здесь надо понимать: при помощи этого метода мы можем учитывать сезонность, тренд и экспоненциальное сглаживание. Метод хольта винтерса может подходить для стабильно продающихся товаров только с ярко выраженным трендом.
Рекомендуем прочитать: Статья "Сравнение Forecast NOW! с методом Хольта-Винтерса" - Прогнозирование методом экспоненциального сглаживания является одним из самых простых способов прогнозирования. Но может ли он конкурировать с современными алгоритмами? Сравнили с нашей программой Forecast NOW!.
Авторегрессия, Arima и другие методы
Позже появились такие модели прогнозирования спроса, как авторегрессия и Arima, где для товаров строится модель спроса и подбираются коэффициенты. Для начала нужно выбрать период регрессии: сколько периодов прошлого брать для прогнозов. Следующий шаг – определить коэффициенты регрессии и постоянную величину.
Прогноз (t+1) = с +εt+ α1 * Продажи (t) +α2 * Продажи (t-1)+ α3 * Продажи(t-2)
• ε t – белый шум
• α – набор коэффициентов,
• с – постоянная константа
Продажи будущего периода мы строим на основании прошлого, подбирая множество наборов коэффициентов.
После того как методы авторегрессии начали расширять, появились такие методики, как Arima+MA (авторегрессия + среднее) и SARIMA: AR+MA+сезонная составляющая. Существует довольно большой пул методов, которые позволяют каким-то образом подобрать эту модель для товара.
Посмотреть сравнение Forecast NOW! c методом авторегресии - Сравнили авторегрессию с Forecast NOW! и разобрали, когда классика проигрывает интеллектуальной модели.
Как подобрать коэффициенты?
Самый большой вопрос во всех этих методах: как правильно подобрать коэффициенты?
Давайте посмотрим на примере для экспоненциального сглаживания, где мы должны подобрать только один коэффициент.

Напомним, чем больше коэффициент α, тем сильнее на нас влияют последние продажи при построении расчётов. Итак, как же происходит подбор коэффициентов?
У нас есть известная история продаж и построенный прогноз. Дальше история продаж делится на два периода. Обычно это периоды 70% и 30%. Если брать в расчёт 100%, то мы рискуем переучить нашу модель, и она будет слишком повторять предыдущие продажи. Поэтому принято делить на 30% на 70%. Для 70% подбирают набор коэффициентов. А на 30% оставшейся истории продаж тестируют коэффициент.
Какие критерии подбора коэффициентов существуют? У нас в примере самый классический критерий оценки ошибки прогнозирования RMSE, или средняя квадратичная ошибка прогнозирования. То есть чем больше будет ошибка прогнозирования, тем менее точным получится прогноз.
Несмотря на то что ошибка прогнозирования наиболее распространенный метод определения точности, мы не рекомендуем его использовать. Об этом мы подробно рассказываем в статье «Почему повышение точности прогноза не гарантирует повышение прибыли. Как привычный показатель вводит компании в заблуждение».
Мы хотим подобрать коэффициент α. Excel позволяет нам это сделать через функцию «Поиск решения» в меню данных. Нажимаем кнопку «Поиск решения» и подбираем оптимальный коэффициент α.
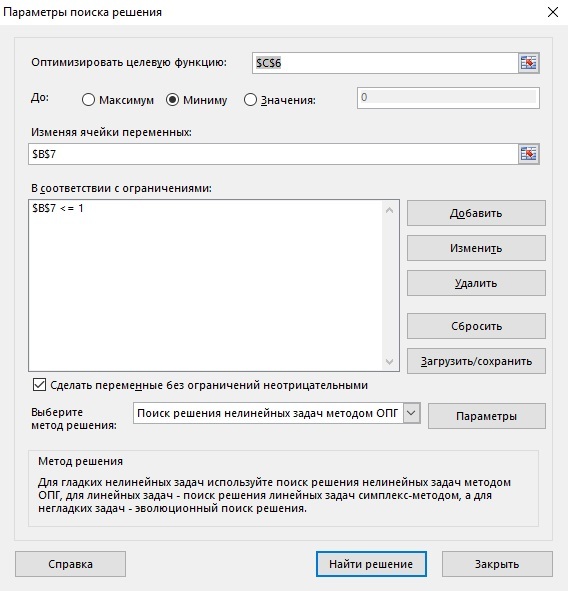
У нас появляется окно, где написано, что мы хотим оптимизировать целевую функцию (это ячейка С6 ошибка RSME). Мы оптимизируем её до минимума, изменяя значения, ячейка B7 – это наша α. Задаём программе параметры, что изменяем, что оптимизируем, какие критерии есть – и находим решение.
Вот Excel подобрал для нас коэффициент:
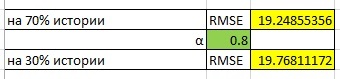 Так выглядит подбор коэффициентов. У нас есть какой-то критерий, и на прошедшей истории продаж мы можем его измерить. Если мы используем какие-то сложные модели и нужно подбирать много коэффициентов, то понадобится специальный софт. Чем больше коэффициентов, тем сложнее это делать. И, естественно, сложнее управлять всем процессом.
Так выглядит подбор коэффициентов. У нас есть какой-то критерий, и на прошедшей истории продаж мы можем его измерить. Если мы используем какие-то сложные модели и нужно подбирать много коэффициентов, то понадобится специальный софт. Чем больше коэффициентов, тем сложнее это делать. И, естественно, сложнее управлять всем процессом.
Общие проблемы методов классического прогнозирования
Главный недостаток этих методов в том, что на выходе мы получаем одно число. Насколько точным может быть этот прогноз? Оценивать спрос одним числом – значит, заведомо ошибаться. Мы никак не управляем уровнем сервиса, не знаем, сколько нам будет стоить привезти необходимый объём запаса под наш прогноз спроса и т. д.
Какие ещё могут быть сложности?
- Методы классического прогнозирования пришли из анализа сильно агрегированных данных. Если у вас сто аналитиков и всего три ряда данных, тогда можно подбирать коэффициенты для каждого ряда данных, анализировать их на стабильность, устойчивость и прочие вещи. В реальности в продажах тысячи товарных позиций на десятках складов. Естественно, подобрать корректно критерии и коэффициенты для такого широкого ассортимента нереально. Это невозможно спрогнозировать.
- Методы классического прогнозирования могут подходить только для товаров продуктовой розницы группы АХ, которые стабильны и постоянно продаются.
Очень часто наши клиенты из компаний, занимающихся розницей, думают, что у них много товаров гладкого спроса. Но по исследованиям гладкие продажи имеют только 6% товаров от всего ассортимента – не больше. (см. научную справку). Если спуститься на уровень торговой точки, то очень мало позиций у нас будут иметь эти самые гладкие продажи.
Рассмотрим это на примере условных булочек.
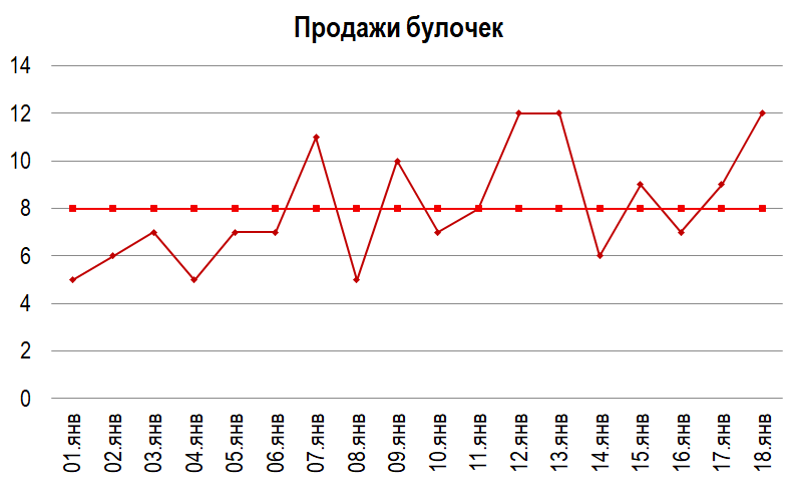
8 булочек - 87% уровень сервиса
По графику видно, что булочки каждый день продаются, и их продажи колеблется от 5 до 12 штук. Если посчитать прогноз по среднему, в день продаётся 8 штук. Если мы будем поддерживать такое количество товара на складе, то для относительно гладко продающейся позиции булочек уровень сервиса будет 87-90. По крайней мере, это какой-то результат, с которым можно работать.
Но если мы перейдём к редко продающимся позициям, картина будет другой. Рассмотрим на примере бытовой химии, которая на уровне конкретной точки продаётся не всегда и хаотично.
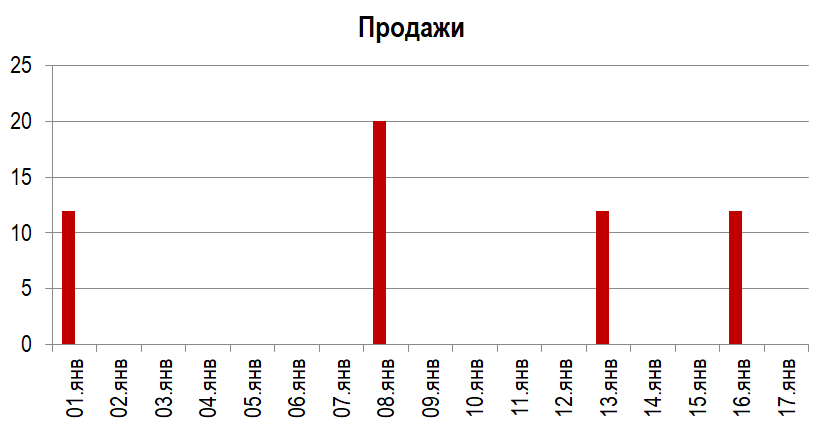
3,29 средства для мытья посуды - 21% уровень сервиса
Если мы построим классический метод прогнозирования, то получим результат 3,29. Согласитесь, что десятые доли здесь выглядят нелепо. Мы не можем хранить на складах 3,29 средства для мытья посуды. Кроме того, если провести линию на графике на уровне 3,29, мы получим уровень сервиса всего 21%. Это говорит о том, что для товаров редкого хаотичного спроса классические методы прогнозирования подходят плохо.
Практические рекомендации
по управлению запасами
Про прогнозирование спроса, управление ассортиментом, планирование запасов, автоматизацию расчетов и сокращение стоков
Рекомендуем прочитать:
Вероятностное прогнозирование спроса: преимущества и методы - Выход за пределы "одного числа": как прогнозировать диапазон спроса с учётом рисков и нестабильности.
Точность прогнозирования или прибыль: что нужно измерять? - Почему ваш идеальный по формуле прогноз может быть убыточным — и что измерять вместо точности.
Формула расчета страхового запаса и пример решения - Даже самый точный прогноз не спасёт, если не заложен буфер. Как правильно рассчитать страховой запас.
Нормирование товарных запасов - Как связать прогноз с реальным количеством товара на складе — без дефицитов и излишков.

